Pandas
Estrategía: Agrupar-Unir-Filtrar
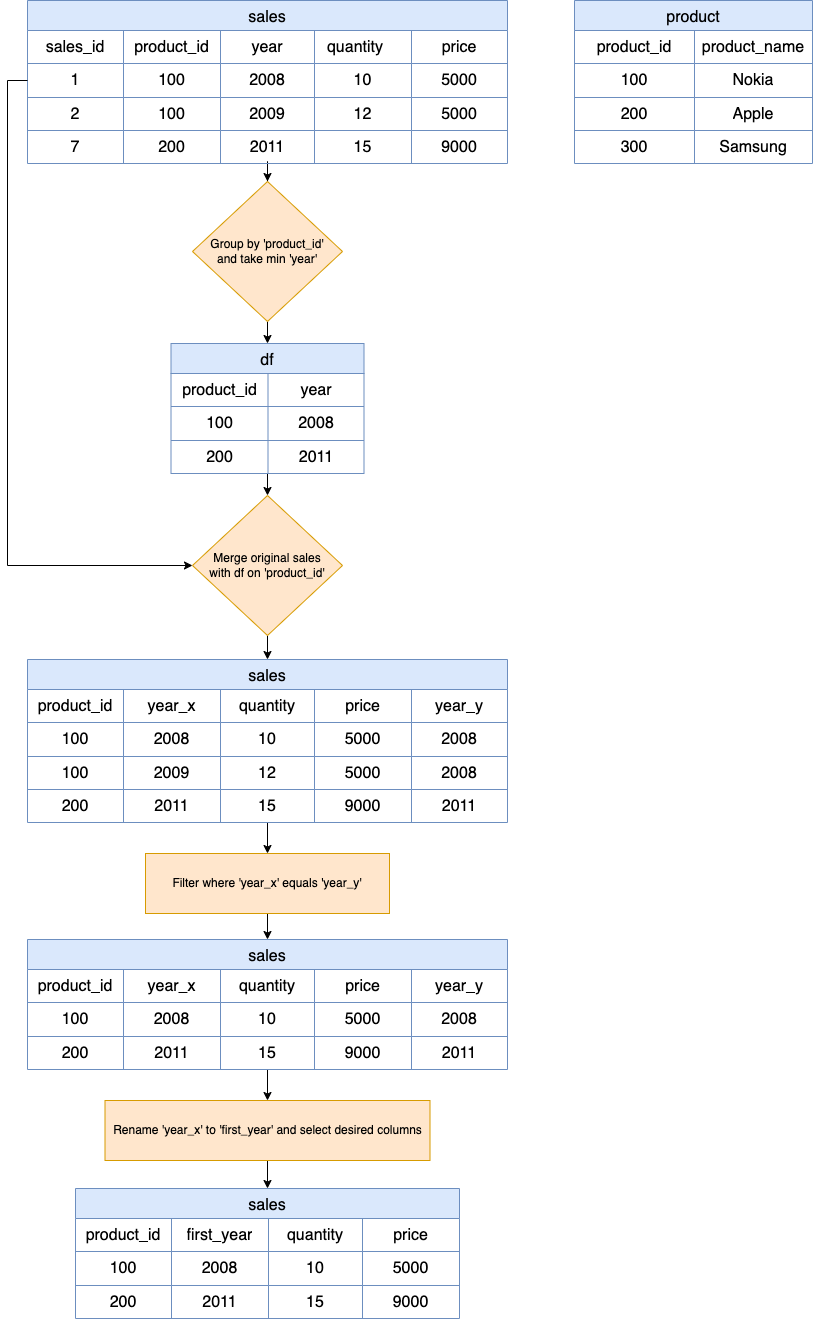
Visualizando la idea general
Intuición
Analicemos el paso a paso usando el siguiente conjunto de datos en los DataFrames:
| sale_id | product_id | year | quantity | price |
|---|
| 1 | 100 | 2008 | 10 | 5000 |
| 2 | 100 | 2009 | 12 | 5000 |
| 7 | 200 | 2011 | 15 | 9000 |
| product_id | product_name |
|---|
| 100 | Nokia |
| 200 | Apple |
| 300 | Samsung |
- Group By & Min
Comenzamos agrupando porque nos permite agregar eficientemente nuestros datos de ventas por producto. Si
obtenemos el año mínimo de cada product_id, podemos identificar rápidamente el año de venta de debut de cada
producto.
df = sales.groupby('product_id', as_index=False)['year'].min()
- Esta línea agrupa las ventas por
product_id y selecciona el año menor en cada grupo, lo cual indica el
primer año en que el producto fue vendido por primera vez. - El DataFrame resultante
df tiene las columnas product_id y year.
df contiene lo siguiente:
| product_id | year |
|---|
| 100 | 2008 |
| 200 | 2011 |
- Unir los DataFrames
Mezclar es un paso natural después de agrupar, especialmente cuando necesitamos filtrar información relacionada
en base al resultado calculado. Al fusionar usando product_id, nos aseguramos que capturamos la tabla
completa de ventas para el año de debut.
sales.merge(df, on='product_id', how='inner')
- Esta línea fusiona el DataFrame original de ventas con el DataFrame
df (que contine el primer año de venta
de cada producto) usando la columna product_id. - Dado que se usa un
INNER JOIN, se conservan solo las filas que aparecen en ambos DataFrames.
sales resultará con la siguiente información:
| product_id | year_x | quantity | price | year_y |
|---|
| 100 | 2008 | 10 | 5000 | 2008 |
| 100 | 2009 | 12 | 5000 | 2008 |
| 200 | 2011 | 15 | 9000 | 2011 |
- Filtrar registros
Esto es escencial para eliminar cualquier dato extraño, asegurando que solo los registros del año de debut del
producto sean preservados. Con este paso, podríamos obtener la información de ventas de los años posteriores
al año de debut, frustrando el propósito del enfoque.
.query('year_x == year_y')
- Después de la fusión, el DataFrame contendrá dos valores para el año, uno por cada DataFrame, renombrados
por pandas como
year_x y year_y. - Esta línea filtra las filas donde
year_x (el año de venta original) es igual al año de debut del producto year_y, conservando solo la información del primer año de venta de cada producto.
sales resultará con la siguiente información:
| product_id | year_x | quantity | price | year_y |
|---|
| 100 | 2008 | 10 | 5000 | 2008 |
| 200 | 2011 | 15 | 9000 | 2011 |
- Renombrar columna y filtrar las columnas deseadas
.rename(columns={'year_x': 'first_year'})[['product_id', 'first_year', 'quantity', 'price']]
- Esta línea renombra la columna
year_x a first_year, haciendo el DataFrame mas entendible. - Finalmente, se seleccionan solo las columnas deseadas, resultando en un DataFrame con las columnas:
product_id, first_year, quantity, y price.
resultado se encuentra en el DataFrame sales:
| product_id | first_year | quantity | price |
|---|
| 100 | 2008 | 10 | 5000 |
| 200 | 2011 | 15 | 9000 |
- Regresar el resultado
Intuitivamente, esta función encuentra el primer año de venta para cada producto y enseguida filtra la
información de ventas correspondiente para esos años.
Implementación
import pandas as pd
def sales_analysis(sales: pd.DataFrame, product: pd.DataFrame) -> pd.DataFrame:
df = sales.groupby('product_id', as_index=False)['year'].min()
filterd_df = sales.merge(
df, on='product_id', how='inner'
).query('year_x == year_y')
filterd_df.rename(
columns={'year_x': 'first_year'},
inplace=True
)
return filterd_df[
['product_id', 'first_year', 'quantity', 'price']
]