Solución - Temperaturas en aumento
Pandas
Vista general
Descripción del problema
Escribe una solución para encontrar todos los Id de las fechas con temperaturas más altas en comparación con sus fechas anteriores (ayer). Regresa la tabla resultado en cualquier orden.
Profundicemos en el ejemplo para entender mejor el problema.
Si realizamos un análisis de series temporales de los datos de temperatura, observaremos distintos puntos en los que se produce un aumento de la temperatura en comparación con el día anterior. Este fenómeno es precisamente lo que nos interesa identificar.
Analizando los datos:
| id | recordDate | temperature |
|---|---|---|
| 1 | 2015-01-01 | 10 |
| 2 | 2015-01-02 | 25 |
| 3 | 2015-01-03 | 20 |
| 4 | 2015-01-04 | 30 |
Podemos representar gráficamente las lecturas de temperatura a lo largo de las fechas consecutivas. Cuando
representamos estos puntos en un gráfico, con el recordDate en el eje X y la temperatura en el eje Y,
observamos una representación gráfica de las variaciones de temperatura a lo largo del periodo especificado.
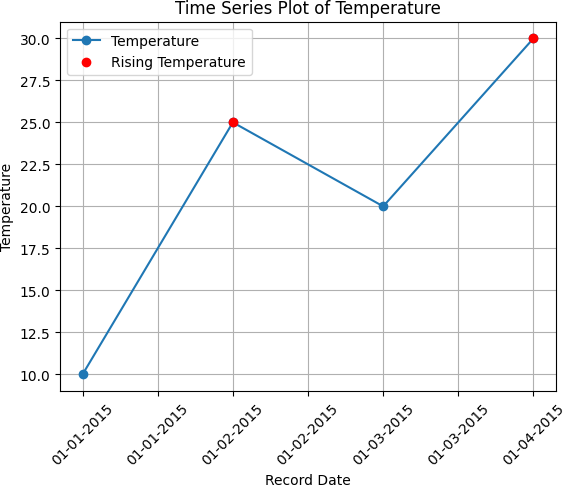
De este análisis gráfico se desprenden dos casos de aumento de la temperatura en comparación con el día anterior:
- 2 de Enero de 2015 (id: 2): En este día, la temperatura fue de 25, misma que es mayor que la registrada el 1ro de Enero (10).
- 4 de Enero de 2015 (id: 4): Aquí, la temperatura subió a 30, superando la temperatura de 20 del 3 de Enero.
Así, según nuestro criterio de identificar los días con un aumento de temperatura respecto al día inmediatamente anterior, deberíamos regresar los ids del 2 de Enero y del 4 de Enero, que son 2 y 4 respectivamente.
Estrategía 1: Fusión de Dataframe desplazados en la fecha de registro
Intuición
Vamos a crear un nuevo DataFrame que representa los datos desplazados un día y enseguida los fusionaremos con
el DataFrame original en función del recordDate. De esta forma, para cada registro, tendremos información
tanto del día actual como del día anterior en la misma fila, lo que permitirá comparar fácilmente las
temperaturas de días consecutivos.
Veamos el paso a paso:
Paso 1: Convertir recordDate a tipo Datetime
# Ensure the 'recordDate' column is a datetime type
weather['recordDate'] = pd.to_datetime(weather['recordDate'])Antes de trabajar con los datos, es una buena práctica asegurarse que le columna que almacena la fecha es del tipo datetime para facilitar las operaciones con fechas:
Paso 2: Crear el DataFrame desplazado
# Create a copy of the weather DataFrame with a 1 day shift
weather_shifted = weather.copy()
weather_shifted['recordDate'] = weather_shifted['recordDate'] + pd.to_timedelta(1, unit='D')Se crea una copia del DataFrame original, donde el recordDate para cada registro se desplaza un día hacia
delante. Esto nos permite fusionar posteriormente este DataFrame con el original para comparar las
temperaturas de cada día con las del día anterior.
Paso 3: Fusionar los DataFrames
# Merging the DataFrames on the 'recordDate' column to find consecutive dates
merged_df = pd.merge(weather, weather_shifted, on='recordDate', suffixes=('_today', '_yesterday'))Los dataframes se fusionan en base a la columna recordDate, la cual contiene fechas consecutivas. Esta
operación forma pares de días consecutivos de tal forma que podemos directamente comparar las temperaturas de
cada día con el día anterior.
Paso 4: Identificar los dias con temperatura más alta que el día previo
# Finding rows where the temperature is greater on the current day compared to the previous day
result = merged_df[merged_df['temperature_today'] > merged_df['temperature_yesterday']][['id_today']].rename(columns={'id_today': 'Id'})Con el último dataframe, aplicamos la condición para retener sólo las filas donde la temperatura del día
actual (temperature_today) es mayor que la del día anterior (`temperature_yesterday). Esto nos dá todos los
días donde la temperatura fue más alta que el día anterior.
Seleccionamos solo la columna ID que corresponde al día que satisface esta condición, y la renombramos a Id para cumplir con la salida esperada.
Paso 5: Regresar el resultado
return resultEl paso final es regresar el DataFrame con los IDs de los días donde la temperatura fue más alta que el día anterior.
Implementación
import pandas as pd
def rising_temperature(weather: pd.DataFrame) -> pd.DataFrame:
# Ensure the 'recordDate' column is a datetime type
weather['recordDate'] = pd.to_datetime(weather['recordDate'])
# Create a copy of the weather DataFrame with a 1 day shift
weather_shifted = weather.copy()
weather_shifted['recordDate'] = weather_shifted['recordDate'] + pd.to_timedelta(1, unit='D')
# Merging the DataFrames on the 'recordDate' column to find consecutive dates
merged_df = pd.merge(weather, weather_shifted, on='recordDate', suffixes=('_today', '_yesterday'))
# Finding rows where the temperature is greater on the current day compared to the previous day
result = merged_df[merged_df['temperature_today'] > merged_df['temperature_yesterday']][['id_today']].rename(columns={'id_today': 'Id'})
return resultEstrategía 2: Usar la función Shift con coincidencia de fecha precisa
Intuición
En este enfoque, ordenamos el DataFrame por recordDate y luego utilizamos la función shift para crear
nuevas columnas que almacenan la información del día anterior. Después, filtramos el DataFrame para incluir
sólo las filas en las que la temperatura es mayor que la del día anterior y las fechas están separadas
exactamente por un día.
Veamos el paso a paso:
Paso 1: Convertir el recordDate a tipo Datetime
weather['recordDate'] = pd.to_datetime(weather['recordDate'])Antes de realizar cualquier operación con fechas, nos aseguramos que le columna recordDate es de tipo
datetime. Esto nos permitirá realizar operaciones con fechas de forma mas sencilla.
Paso 2: Ordenar el DataFrame
weather.sort_values('recordDate', inplace=True)Ordenamos la información por recordDate para mantener un órden cronológico. Este paso es crucial porque los
siguientes pasos dependen del orden de las fechas.
Paso 3: Crear columnas para los datos del día previo
weather['PreviousTemperature'] = weather['temperature'].shift(1)
weather['PreviousRecordDate'] = weather['recordDate'].shift(1)Creamos dos nuevas columnas en el DataFrame weather:
PreviousTemperature: esta columna se construye desplazando la columnatemperatureuna fila hacia abajo utilizandoshift(1). Esto significa que el valor de cada fila dePreviousTemperaturees el valor de la temperatura inmediatamente anterior en el DataFrame, no necesariamente del día inmediatamente anterior (en terminos de tiempo).PreviousRecordDate: Similarmente, esta columna se forma desplazando la columnarecordDateuna fila hacia abajo. Por tanto, cada valor enPreviousRecordDatecorresponde al de la fecha de la fila inmediatamente anterior, no necesariamente del día inmediatamente anterior alrecordDateactual.
Al tener estas nuevas columnas, alineamos cada fila con la temperatura y la fecha de registro de su fila precedente en el DataFrame, permitiendo comparaciones entre la temperatura de un día y la de la fila anterior. Es crucial tener en cuenta que estos valores ‘anteriores’ provienen del orden del DataFrame y no siempre representan el día cronológico anterior, ya que puede haber lagunas en las fechas dentro de los datos.
Paso 4: Filtrar por días con temperatura más alta que el día anterior
result = weather[
(weather['temperature'] > weather['PreviousTemperature']) &
(weather['recordDate'] == weather['PreviousRecordDate'] + pd.Timedelta(days=1))
][['id']].rename(columns={'id': 'Id'})Filtramos el DataFrame por filas donde la temperatura es mayor que la temperatura del día anterior:
(weather['temperature'] > weather['PreviousTemperature']).
También nos aseguramos que la fecha de registro es exactamente un día mayor a la del día anterior:
(weather['recordDate'] == weather['PreviousRecordDate'] + pd.Timedelta(days=1)). Esto se realiza usando pd.Timedelta(days=1) para agregar un día a la fila anterior y verificar si es igual a la fila actual.
Paso 5: Regresar el resultado
return resultFinalmente, regresamos el DataFrame filtrado, el cual contiene solo la columna Id que satisface ambas
condiciones especificadas en el paso 4. Este DataFrame representa todas las fechas donde la temperatura fue
más alta que la temperatura del día anterior.
Implementación
import pandas as pd
def rising_temperature(weather: pd.DataFrame) -> pd.DataFrame:
# Ensure the 'recordDate' column is a datetime type
weather['recordDate'] = pd.to_datetime(weather['recordDate'])
# Sorting the DataFrame by 'recordDate' to ensure the shift operation works correctly
weather.sort_values('recordDate', inplace=True)
# Creating new columns for the previous day's temperature and record date
weather['PreviousTemperature'] = weather['temperature'].shift(1)
weather['PreviousRecordDate'] = weather['recordDate'].shift(1)
# Filtering the DataFrame to find rows where the temperature is higher
# than the previous day and the date is exactly one day more than the previous record date
result = weather[
(weather['temperature'] > weather['PreviousTemperature']) &
(weather['recordDate'] == weather['PreviousRecordDate'] + pd.Timedelta(days=1))
][['id']].rename(columns={'id': 'Id'})
return result